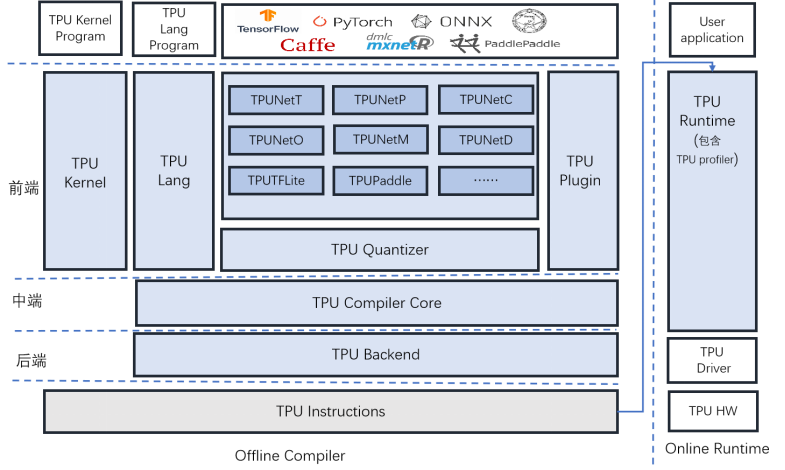
-
Products
-
Ecological Products
-
Industry Solutions
-
Processors
-
Servers
-
Modules & Cards
TPU Processors
-
 BM1688
BM1688TPU processor, 16 channels HD video intelligent analysis, 16 channels of full HD video decoding, 10 channels of full HD video encoding
-
 BM1684X
BM1684XTPU processor, 32 channels HD video intelligent analysis, 32 channels of full HD video decoding, 12 channels of full HD video encoding
RISC-V Processors
-
 SG200X
SG200XRISC-V + ARM intelligent deep learning processor
-
 SG2042
SG2042Based on the RISC-V core, operating at a frequency of 2GHz, the processor features a single SOC with 64 cores and 64MB shared L3 cache.
Deep Learning Vision Processors
-
 CV186AH
CV186AH16M High-end Intelligent Deep Learning Vision Processor
-
 CV184xC-P
CV184xC-PTerminal AI Vision Processor
-
CV184xH-P
Terminal AI Vision Processor
-
 CV180xB
CV180xBBased on RISC-V 3-5M slightly intelligent deep learning vision processor
-
CV181xH
Based on RISC-V 5M light intelligent deep learning vision processor
-
CV181xC
RISC-V 5M light intelligent deep learning vision processor
-

-

-
-

-

-
-
 Micro Server SE7 32-EA4-23
Micro Server SE7 32-EA4-23BM1684X, 32-channel HD Video Analysis
-
 Micro Server SE7 32-BP1-11
Micro Server SE7 32-BP1-11BM1684X, 32-channel HD video intelligent analysis
-
 Micro Server SE7 32-EP1-21
Micro Server SE7 32-EP1-21BM1684X, 32-channel HD video intelligent analysis
-
 RISC-V 42U Server Cluster SRC1-10spot
RISC-V 42U Server Cluster SRC1-10spotSRC1-10 is an excellent performance server cluster based on RISC-V arch. It has both computing and storage capabilities, and the full stack of software and hardware is domestically produced.
-
 RISC-V Fusion Server SRM1-20spot
RISC-V Fusion Server SRM1-20spotThe RISC-V Fusion Server, supports dual-processor interconnection and enabled intelligent computing acceleration.
-
 RISC-V Storage Server SRB1-20spot
RISC-V Storage Server SRB1-20spotSRB1-20 is an excellent performance storage server based on RISC-V arch. It supports CCIX, 128-core concurrent, multi-disk large-capacity secure storage, and the full stack of software and hardware is domestically produced.
-
 RISC-V Compute Server SRA1-20spot
RISC-V Compute Server SRA1-20spotSRA1-20 is an excellent performance computing server based on RISC-V arch. It supports CCIX, 128-core concurrent, both software and hardware are open source and controllable.
-
 RISC-V Compute Server SRA3-40
RISC-V Compute Server SRA3-40SRA3-40 is a RISC-V server for high-performance computing, domestic main processor,excellent performance,fusion of intelligent computing, support powerful codec.
-
RISC-V Storage Server SRB3-40
SRB3-40 is a high-performance RISC-V storage server with multiple disk slots and large-capacity secure storage.
-
Module
-
Board Card
-
Developer Kits
-
Computing Power Machine
-
 Deep Learning Module
Deep Learning ModuleSOM1684, BM1684, 16-Channel HD Video Analysis
-
 Artificial Intelligence Core Board
Artificial Intelligence Core BoardCore-1684-JD4,BM1684, 16-Channel HD Video Analysis
-
 Deep Learning Module
Deep Learning ModuleSBC-6841,BM1684, 16-Channel HD Video Analysis
-
 Deep learning Core Board
Deep learning Core BoardiCore-1684XQ,BM1684X,32-Channel HD Video Analysis
-
 Deep learning Core Board
Deep learning Core BoardCore-1684XJD4,BM1684X,32-Channel HD Video Analysis
-
 Development Board
Development BoardShaolin PI SLKY01,BM1684, 16-Channel HD Video Analysis
-
 Deep learning Module
Deep learning ModuleQY-AIM16T-M,BM1684, 16-Channel HD Video Analysis
-
 Deep Learning Module
Deep Learning ModuleQY-AIM16T-M-G,BM1684, 16-Channel HD Video Analysis
-
 Deep Learning Module
Deep Learning ModuleQY-AIM16T-W,BM1684, 16-Channel HD Video Analysis
-
 Deep Learning Accelerator Card
Deep Learning Accelerator CardAIV02T,1684*2,Half-Height Half-Length Accelerator Card
-
 Deep Learning Mainboard
Deep Learning MainboardAIO-1684JD4,BM1684, 16-Channel HD Video Analysis
-
 Deep Learning Mainboard
Deep Learning MainboardAIO-1684XJD4,BM1684X,32-Channel HD Video Analysis
-
 Deep learning Mainboard
Deep learning MainboardAIO-1684XQ,BM1684X,32-Channel HD Video Analysis
-
 Deep Learning Workstation
Deep Learning WorkstationIVP03X,BM1684X,32-Channel HD Video Analysis
-
 Deep Learning Workstation
Deep Learning WorkstationIVP03A,Microserver, passive cooling, 12GB RAM
-
 Edge Deep Learning Computer
Edge Deep Learning ComputerCoeus-3550T,BM1684, 16-Channel HD Video Analysis
-
 Deep Learning Intelligent Computing Box
Deep Learning Intelligent Computing BoxEC-1684JD4,BM1684, 16-Channel HD Video Analysis
-
 Deep learning Cluster Server
Deep learning Cluster ServerCSA1-N8S1684,BM1684*8,1U Cluster Server
-
 Electronic Seal Analyzer
Electronic Seal AnalyzerDZFT-ZDFX,BM1684X,Electronic Seal Analyzer,ARM+DSP architecture
-
 Video Intelligent Identification and Analysis Device
Video Intelligent Identification and Analysis DeviceZNFX-32,BM1684, 16-Channel HD Video Analysis
-
 Flameproof and Intrinsic Safety Analysis Device
Flameproof and Intrinsic Safety Analysis DeviceZNFX-8,BM1684X,ARM+DSP architecture,Flameproof and Intrinsic Safety Analysis Device
-
 High Computing Power Deep Learning Server
High Computing Power Deep Learning ServerEC-A1684JD4,Microserver with active cooling, 16GB RAM, 32GB eMMC
-
 High Computing Power Deep Learning Server
High Computing Power Deep Learning ServerEC-A1684JD4 FD,BM1684, 16-Channel HD Video Analysis,6GB of RAM, 32GB eMMC
-
 High Computing Power Deep Learning Server
High Computing Power Deep Learning ServerEC-A1684XJD4 FD,BM1684X,32-Channel HD Video Analysis
-
 Deep Learning Edge Computing Box
Deep Learning Edge Computing BoxECE-S01, BM1684, 16-Channel HD Video Analysis
-
 Intelligent analysis device for prohibited items
Intelligent analysis device for prohibited itemsIOEHM-AIRC01,BM1684,Microserver Active Cooling,16-Channel HD Video Analysis
-
 Deep learning video capture and analysis device
Deep learning video capture and analysis deviceIOEHM-VCAE01, BM1684, 16-Channel HD Video Analysis
-
 Deep Learning Cluster Server
Deep Learning Cluster ServerCSA1-N8S1684X,BM1684*8,1U Cluster Server
-
 Deep Learning Server
Deep Learning ServerQY-S1U-16, BM1684, 1U Server
-
 Deep Learning Cluster Server
Deep Learning Cluster ServerQY-S1U-192, BM1684*12, 1U Cluster Server
-
 Deep Learning Cluster Server
Deep Learning Cluster ServerQY-S1X-384, BM1684*12, 1U Cluster Server
-
Smart Governance
-
Smart Transportation
-
Smart Public Security
-
Large-scale Property Management
-
Smart Business Hall
-
Safety Production
-
Energy and Petrochemicals
-
Intelligent Computing Center
-
Algorithm Training and Promotion Integration
-
Urban Management
Deep learning intelligent analysis helps make city management more efficient and precise
-
Environmental protection dust control
Using deep learning video technology to analyze sources of dust generation and dust events, contributing to ecological environmental protection
-
Emergency Monitoring
Using deep learning intelligent analysis to monitor scenarios such as safety production, urban firefighting, and unexpected incidents for emergency regulation.
-
Grassroots Governance
Using deep learning technology to detect and analyze individuals, vehicles, and security incidents in grassroots governance
-
Vehicle Big Data
Empowering the problems of traffic congestion, driving safety, vehicle violations, and road pollution control
-
Full-Object Video Structuring
Utilizing domestically developed computational power to support the structured analysis of massive volumes of videos, catering to practical applications in law enforcement
-
Gait Big Data
Build a "smart, collaborative, efficient, innovative" gait recognition big data analysis system centered around data
-
Comprehensive Treatment Of High-altitude Littering
Effectively resolving incidents of objects thrown from height, achieving real-time monitoring of such incidents, pinpointing the location of the thrown object, triggering alerts, and effectively safeguarding the safety of the public from falling objects
-
Smart Community
Using edge computing architecture to timely and accurately monitor community emergencies and safety hazards
-
Smart Hospital
SOPHGO with SOPHON.TEAM ecosystem partners to build a deep learning supervision solution for smart hospitals, enhancing safety management efficiency in hospitals
-
Smart and Safe Campus
SOPHGO with SOPHON.TEAM ecosystem partners to build a smart safe campus solution
-
Bright Kitchen and Stove
Using a combination of cloud-edge deep learning methods to address food safety supervision requirements across multiple restaurant establishments, creating a closed-loop supervision system for government and enterprise-level stakeholders
-
General Safety Production
SOPHON's self-developed computing hardware devices, such as SG6/SE5/SE6, equipped with SOPHON.TEAM video analysis algorithms, are used to make industrial safety production become smarter
-
Smart Gas Station
Combining deep learning, edge computing and other technologies, it has the ability to intelligently identify people, objects, things and their specific behaviors in the refueling area and unloading area. It also automatically detects and captures illegal incidents at gas stations to facilitate effective traceability afterwards and provide data for safety management.
-
Three No's Industrial Park
SOPHGO, in collaboration with SOPHON.TEAM and its ecosystem partners, is focusing on three major scene requirements: "Production Safety Supervision," "Comprehensive Park Management," and "Personnel Safety & Behavioral Standard Supervision." Together, they are developing a comprehensive deep learning scenario solution, integrating "algorithm + computing power + platform."
-
Smart Chemical Industrial Park
SOPHGO, cooperates with SOPHON.TEAM ecological partners to build a deep learning monitoring solution for safety risks in chemical industry parks
-
Intelligent Computing Center
SOPHGO with SOPHON.TEAM ecosystem partners to build a Smart Computing Center solution, establishing a unified management and scheduling cloud-edge collaborative smart computing center
-
Algorithm Training and Promotion Integration
SOPHGO, in collaboration with SOPHON.TEAM ecosystem, have jointly developed a set of hardware leveraging domestically-produced deep learning computational power products. This is based on an AutoML zero-code automated deep learning training platform, enabling rapid and efficient implementation of deep learning engineering solutions